Memory-based deep learning architectures for global weather forecasting
Motivation
Computational weather forecasting simulations are costly and inaccurate.
Deep learning alternatives such as Pangu-Weather1, GraphCast2, provide simulation-level accuracy by ingesting a glut of variables that represent current system state, training next-step prediction.
As this system state is only partially observable, we investigate alternative memory-based approaches via the Mori-Zwanzig formulation3.
Learning the Dynamics of a Partial Observation
Assume weather system is autonomous given enough physical variables: \[ \frac{d\mathbf{x}}{dt} = \mathbf{f(x)} \text{, and } \mathbf{x_0}:=\mathbf{x(t_0)} \text{, with unknown } \mathbf{f}:\mathbb{R}^n \rightarrow \mathbb{R}^n \] Realistically the weather system state, \(\mathbf{x}\), is only partially known. \[ \text{Let }\mathbf{z}\in\mathbb{R}^d\text{ be observable, s.t. }\mathbf{x}=\mathbf{[z\text{ }w]}\text{ and }\mathbf{w}\in\mathbb{R}^{n-d}\text{ hidden with } n » d \] Applying the Mori-Zwanzig formulation3, we find additional memory functions (K,F) in the observable dynamics. \[ \frac{d}{dt}\mathbf{z}(t) = \mathbf{R}(\mathbf{z}(t)) + \int_{0}^t \mathbf{K}(\mathbf{z}(t-s),s)ds + \mathbf{F}(t,\mathbf{x_0}) \] So flow-map learning (below) as in Pangu-Weather1 and GraphCast2 is insufficient. \[ \frac{d}{dt}\mathbf{z}(t) \approx \mathbf{R}(\mathbf{z}(t)) \]
Memory-based Architectures

![]()
Tests are performed on PredRNN5 (a convolutional LSTM), LSTM, BERT6 (en/decoder-only temporal transformer), and ReZeroTF (reZero7 architecture, en/decoder-only transformer).
PDE Prediction
- Rayleigh-Bénard PDE problem for preliminary testing
\[ \frac{\partial{u}}{\partial{t}} = 0.05 * [\nabla\cdot\nabla u - \nabla \cdot (u\mathbf{v}) + u(1-u^2)]\text{, where } \mathbf{v}=0.1 <-y,x> \]
- Note no hidden variables (single-variable system)
- PredRNN and ReZero transformer performed best
- PredRNN is less dependent on memory length.
- 30 frames seems to be a limit for a 40-frame set.
| MSE | 3 Frames | 10 Frames | 20 Frames |
|---|---|---|---|
| PredRNN | 0.022 | 0.016 | 0.011 |
| ReZeroTF | 0.259 | 0.053 | 0.024 |
Direct Prediction (PDE)
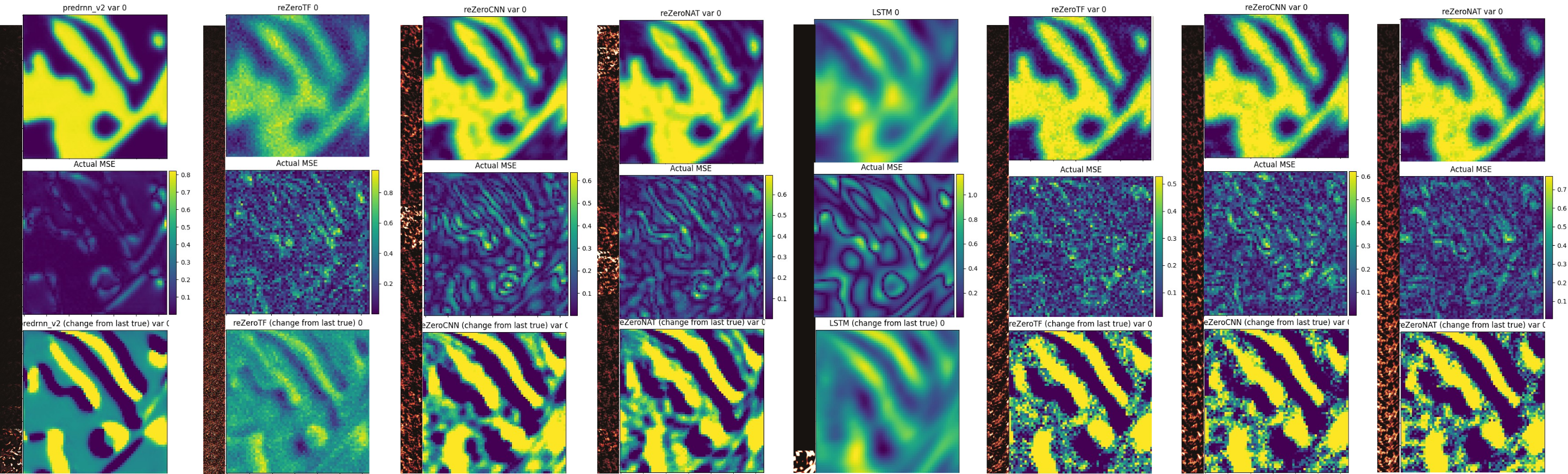
- ReZero uses FCN layers, so pointwise behavior results in noisy output.
- PredRNN applies CNN filters to produce a smooth result.
So variants replacing the transformer FCN layers with CNN or NAT (neighborhood attention) layers improve with sparser attention and smoother output respectively.
| - | PredRNN | ReZero | ReZeroCNN | ReZeroNAT |
|---|---|---|---|---|
| MSE | 0.01 | 0.07 | 0.04 | 0.036 |
Reduced Order : POD & DMD
| MSE | PredRNN | LSTM | ReZeroCNN | ReZeroNAT |
|---|---|---|---|---|
| POD | 0.7400 | 0.4902 | 0.1214 | 0.0985 |
| DMD | 0.1882 | 0.1028 | > 1 | > 1 |
- The (best) LSTM and reZeroTF shown have relative MSE 17% and 3.5% respectively. Note the LSTM also learns that memory is redundant!
- As expected, LSTM performs best with a linear preprocessor, while the transformer performs best with independent axes (from POD).
- The CNN and NAT variations do not improve performance (5 and 5.3% relative MSE).
- *ReZeroTF and LSTM with POD have differing scales, and the saliency maps shown are for a different, but consistent prediction.
The first four are Direct Prediction, the last four are Reduced Order.

Weather Prediction (PredRNN)
Preliminary testing produces acceptable results for PredRNN on ERA5 weather data4.
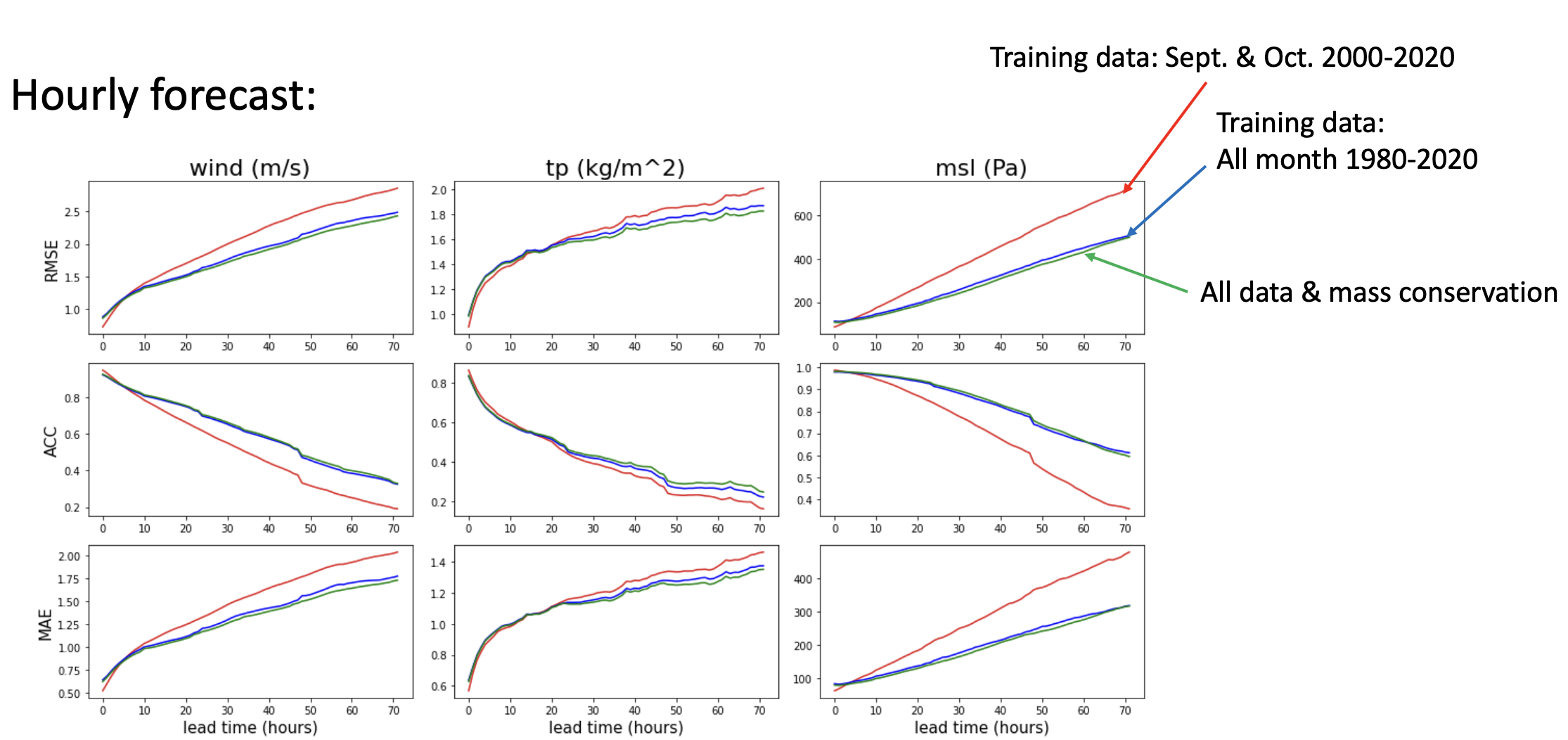
Weather Prediction (POD) // Ongoing Work
POD correlations capture rain-shadow effects, geostrophic flow, etc. that otherwise require extensive spatial modeling.

- PredRNN and convolutional methods like CNN work best for direct learning in observable systems, but reduced-order modeling with POD and transformers can provide comparable accuracy.
- PredRNN is capable in latent-variable systems, but POD methods show promise at easily capturing complex inter-variable relations.